
Since the middle of last year, we have been working on a new infrastructure for the WEDOS Global Protection (WGP) service. The goal was to build a solution that is more robust, faster, easier to maintain, and capable of deploying more advanced detection mechanisms.
The new infrastructure allows us to analyze not only HTTP headers, but also request content and even metadata at the TLS communication layer. This opens the door to techniques such as JA4 and JA4H fingerprinting, as well as other more universal detection methods.
In January 2026, the gradual migration to the new solution was completed. At this point, all customers using WEDOS Global Protection should already be running on it. If you have an active WGP service and access to the administration interface, you have probably noticed a number of new options for creating rules. The administration interface itself will still undergo further changes.
Why we cannot be too strict
With the new infrastructure, we are technically capable of implementing protection that could, in many cases, replace a conventional WAF for web traffic on ports 80 and 443. That does not mean, however, that this is always the right approach.
In real-world traffic, there is a large number of non-standard applications and API interfaces. If we make the rules too strict, we will start breaking legitimate customer traffic. That is why rules must be designed with great care.
Security is always a balance between:
- infrastructure protection
- service stability
- compatibility with customer applications
That is exactly why we have defined processes that determine how we respond to new types of attacks.
A wave of vulnerability scanning using EXTRACTVALUE
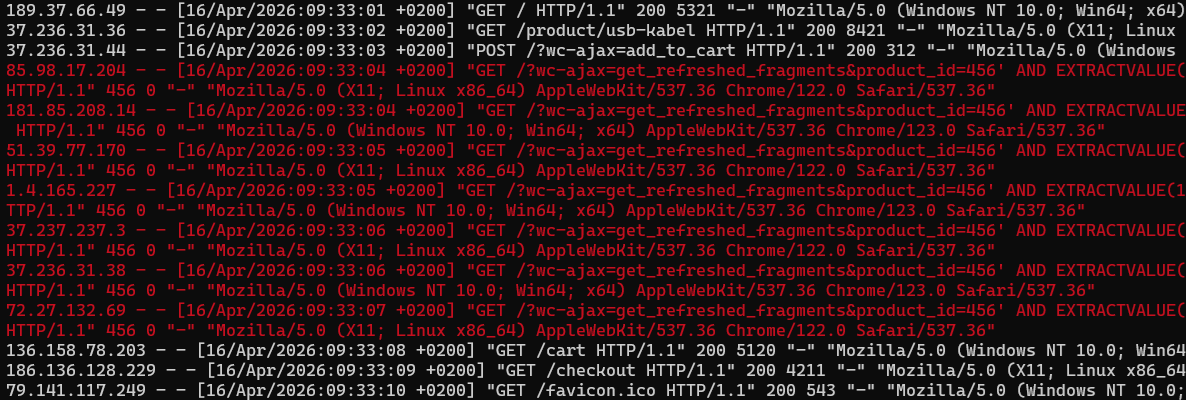
Last week, we observed increased activity of automated vulnerability scanning focused on SQL injection techniques using the EXTRACTVALUE function.
This is not a new technique. It has been known for more than ten years and belongs to the category of so-called error-based SQL injection. Even so, it regularly returns in waves whenever new vulnerabilities in widely used applications are disclosed.
The principle is simple.
The EXTRACTVALUE() function in MySQL/MariaDB is used for working with XML data. If it receives invalid input, it returns an error message. And it is precisely into that error message that data from the database can be inserted.
A sample payload may look like this:
EXTRACTVALUE(1, CONCAT(':', (SELECT user())))The result is a database error which, under ideal conditions for the attacker, would look like this:
XPATH syntax error: ':root@localhost'In other words:
- the application returns an error
- the error contains data from the database
- the attacker gains information without needing the application to display any normal output
That is why this technique is used in automated scanners: it is simply straightforward, fast, and reliable.
Why this technique appeared right now
In recent months, a larger number of SQL injection vulnerabilities have been published in various web applications and plugins. As soon as such a vulnerability appears in CVE databases or exploit databases, automated tools begin scanning the internet and testing exposed services within a short period of time.
For example:
- in February 2026, vulnerability CVE-2026-24419 was disclosed in OpenSTAManager, allowing data to be extracted from the database specifically through the
extractvalue()orupdatexml()functions via database error messages - other SQL injection vulnerabilities were published in various web applications and systems, for example CVE-2025-34038, where arbitrary SQL queries could be executed through an unsanitized parameter in an HTTP request
- similar issues appear repeatedly in plugins and web applications where the application directly uses user input when building SQL queries without properly sanitizing that input
Once such a vulnerability is disclosed, the typical sequence looks like this:
- vulnerability disclosure
- release of an exploit or proof-of-concept
- automated internet-wide scanning
- attempts to identify vulnerable systems
So this is not a targeted attack against one specific website. It is systematic testing of a large number of systems, which can very easily turn into a kind of smaller DDoS event.
What the specific scanning looked like
Below is an example of real-world scanning of an online store with very well-optimized code, so it managed to withstand the attack, but it still slowed down significantly. Incidentally, this is our VEDOS NoLimit Extra, which became noticeably faster after major optimizations at the beginning of the year.
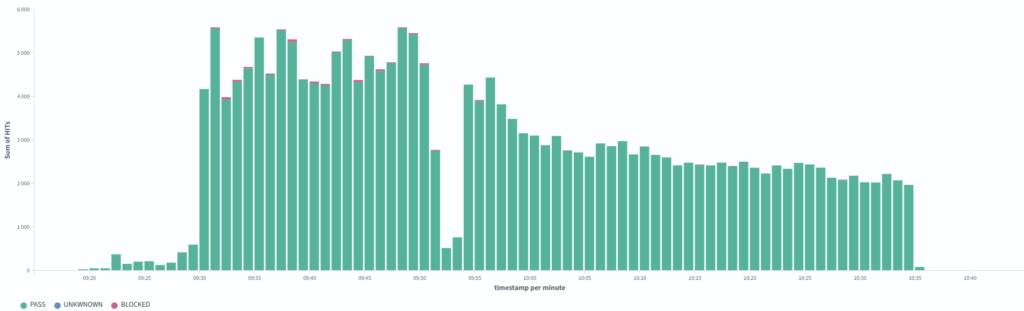
Summary data:
- 1 target domain
- 56 Points of Presence (PoPs) through which the traffic passed
- 19,858 unique IP addresses
- 218,577 legitimate-looking HTTP requests
- attack duration of approximately 1.5 hours
The attacker regulated the number of requests very carefully.
During the entire event:
- only 1 IP exceeded 500 requests
- only 9 IPs exceeded 100 requests
- most IPs generated only a few dozen requests
This is typical behavior for modern scanners looking for vulnerabilities. A year ago, this would have been something unusual and carefully targeted; today, things like this are routine in mass scanning.
This is not about overloading the server with an enormous traffic volume. It is long-term, distributed vulnerability testing. However, when you add a few thousand requests per minute against forms on top of normal traffic, it becomes noticeable. And not everyone has a website as well-optimized as one running on NoLimit Extra 😉
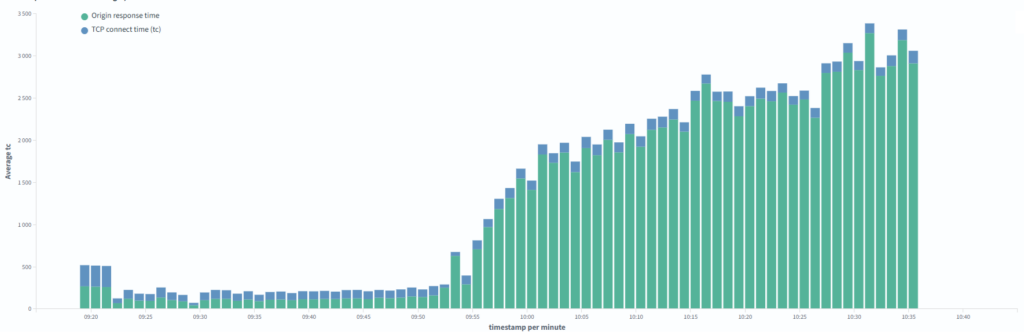
On the other hand, the website gradually started slowing down as a result of the attack, and the impact became noticeable. In the graph, you can see the connection duration to the origin server and the response time.
What makes this interesting from a defensive point of view
The attacker used several techniques that allowed them to bypass basic automatic blocking:
- low request volume per single IP address
- distributed traffic from a large number of sources
- obfuscated SQL payloads
- absence of typical attack signatures
- gradual server load increase
- and a few others that we cannot present publicly
This is important. Traditional rate-limiting mechanisms do not work well in such a case because:
- each IP generates only a small number of requests
- the traffic is spread out over time
- the requests look relatively normal
If they optimized it further, even 1–2K requests per minute might go unnoticed from a performance perspective. And that is already a lot.
What this means for infrastructure protection
Today, attacks like this represent typical “traffic” on the internet. They are no longer exceptional events. We block this type of traffic in higher tens of percent.
SQL injection has long been one of the most common web vulnerabilities and still keeps appearing in new applications, often due to improper handling of input when building SQL queries. In most cases, protection lies on the side of the script developer, who should properly sanitize those inputs. Even so, a few thousand requests into forms are still a substantial load that you simply cannot serve from cache.
From an infrastructure perspective, this means:
- the attack does not have to take the server down
- but it can slow it down significantly
- and generate unnecessary load
That is why it is important to respond quickly, but also carefully.
We have been dealing with SQL injection for a long time, but cautiously
SQL injection attacks are nothing new. They are among the oldest-known and most common web vulnerabilities, and they continue to appear in many forms almost constantly.
That is why, within WEDOS Global Protection, we had already implemented a set of rules targeting the most common techniques, for example:
- time-based SQL injection (
sleep(),pg_sleep()) - attempts to read files from the filesystem (
load_file()) - classic injection patterns (
union select,or 1=1) - attempts to manipulate SQL comments
- other typical signatures used by automated tools
We have been using these rules for a long time and they work very well. At the same time, we use them carefully. The reason is simple. A large number of customers use API interfaces that may contain:
- SQL-like queries
- filter expressions
- custom query syntax
- non-standard parameters
If we made the rules too strict, we would start blocking legitimate traffic. That is why we try to follow one principle: detect the specific attack technique, not general keywords
Why we had not deployed the new rule earlier
We had already prepared a rule against SQL injection via EXTRACTVALUE() earlier.
It was not a new idea. However, in historical testing on real traffic data, it ran into one problem: false positives.
Specifically, some non-standard customer API requests contained similar constructs such as:
- functions
- parentheses
- text expressions
- parameter combinations
A simple detection rule would therefore have led to blocking legitimate traffic. That is a situation we try to avoid at all costs — especially because WGP protects VEDOS services where customers do not necessarily expect this layer of protection.
From an infrastructure point of view, it is worse to break a customer’s script than to let a single scanning request pass through. After all, unsanitized script inputs are the website owner’s responsibility.
What changed
The current wave of scanning changed the situation. It is massive, professional, and it is not going after individual customers. Literally anyone can become a target. On top of that, it avoids a number of detection techniques quite effectively.
We have several ways to handle this, but let’s say that this particular SQLi technique clearly deserved its own dedicated rule. So we reopened an older issue, compared the original proposals, OWASP recommendations, and the new data.
Since the original proposal, we have moved forward significantly, and some false positives can now be handled differently if needed. That is how the concept of a new rule emerged.
How the rule was tested and deployed
Deploying a new rule does not happen in a single step. It is a controlled process. The typical workflow is:
1) rule design
Goal:
- detect the specific attack technique
- minimize false positives
- maintain low computational overhead
2) testing in an isolated environment
We verify:
- functionality
- performance
- stability
For example:
- whether the rule correctly detects the payload
- whether it avoids blocking normal requests
- whether it increases latency
3) backtesting on real-world data
This is the key phase. We use historical logs from production traffic and simulate:
- normal traffic
- API requests
- known attacks
The goal is to determine:
- how many attacks the rule will catch
- how many legitimate requests it would block
In this specific case, the result was:
- 100% detection of the current scanning wave
- 0 false positives in the tested data
- more than 99.9% detection of older SQLi attacks
That is a very good compromise in a shared hosting environment.
Why 100% detection of all SQL injection is not the goal
This is important to explain. WEDOS Global Protection is not a replacement for securely written scripts. New variants keep appearing all the time, and by the time we create a rule for them, it may already be too late. At the same time, it is not possible to create universal rules that fit everyone. What works well for a blog or an online store will not necessarily work correctly for an API.
Responsibility for application security always remains with the developer.
Our main goal is to:
- reduce infrastructure load
- limit automated scanning
- improve service stability
Final review and deployment
Once testing is complete, the final review follows. This includes manual review by the security team and developers. We focus mainly on:
- performance review — the rule must not be unnecessarily expensive
- traffic simulation — this is more about determining which layer should carry the rule
- analysis of possible weaknesses — we must consider many other rules and, above all, user-defined rules
At this stage, we also use automated tools for rule analysis, including machine learning models that help identify potential issues or unexpected scenarios.
Only after that does deployment take place.
In this specific case, the time from detecting the attack to deploying the rule was approximately 4 days.
However, in a critical situation, we are able to distribute new rules very quickly. From the moment a rule is entered into the system, we currently manage to deploy it to approximately 90% of locations within 5 minutes and to all locations within about 15 minutes.
Distribution runs in parallel across all infrastructure locations. Our goal is global deployment within 5 minutes. That is a technical target we are currently working toward.
Conclusion
Waves of vulnerability scanning like this have become a normal part of internet traffic today. These are not exceptional events, but a continuous process that repeats every time a new vulnerability or exploit is disclosed.
Our goal is not to block every single attack attempt at any cost.
Our goal is to keep the infrastructure stable, minimize unnecessary server load, and respond quickly to new techniques as they appear in real-world traffic.
The new WEDOS Global Protection infrastructure gives us significantly better capabilities in this area.
This specific case shows how the response to new types of “non-acute” attacks works in practice today — from identifying the problem through data analysis all the way to deploying a rule into production.
Security is not a one-time setting. It is a continuous process. And that is exactly the philosophy on which WEDOS Global Protection is built.